KEDA
KEDA — Kubernetes-based Event-Driven Autoscaler — es un Addon que permite escalar workloads de tu Clúster en base a señales externas: la cantidad de mensajes en una cola SQS, el lag de un consumer group de Kafka, una alarma de CloudWatch, la cantidad de claves pendientes en Redis, el número de filas en una base de datos, y decenas más. Mientras que el HPA nativo de Kubernetes solo escala según CPU y memoria de los Pods, KEDA consulta la fuente externa, pregunta cuánto trabajo está pendiente, y escala el workload acorde — incluso bajando a cero réplicas cuando no hay nada para procesar.
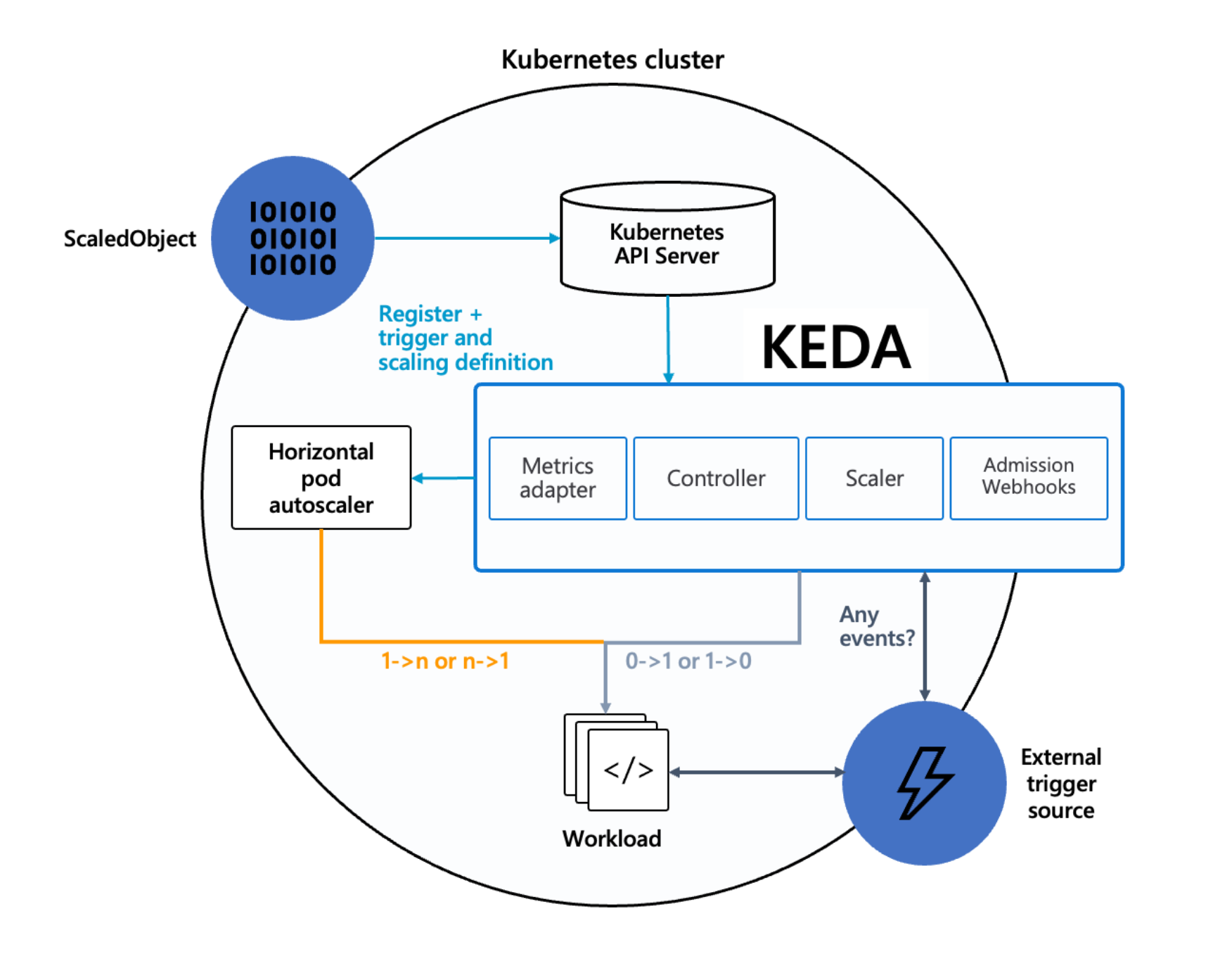
SleakOps instala el operador de KEDA y configura los permisos de IAM que necesita para leer métricas de AWS. Vos después definís las reglas de escalado para cada Workload como manifiestos de Kubernetes (recursos ScaledObject) — KEDA lee esos manifiestos, observa los triggers configurados, y ajusta las réplicas detrás de escena.
El addon de KEDA se encuentra en Beta. La instalación y el cableado de permisos de AWS son estables, pero la configuración subyacente puede seguir evolucionando.
Preguntas Frecuentes
¿Qué es KEDA y cuándo conviene usarlo?
Usá KEDA cada vez que la señal natural de escalado para un Workload viva fuera del Pod. Casos típicos en SleakOps:
- Un worker que consume una cola SQS — escalá el Deployment en base a la profundidad de la cola, hasta cero entre ráfagas.
- Un consumer de un topic de Kafka — escalá según el lag del consumer group en lugar de CPU.
- Un batch programado — escalá con un trigger cron y volvé a cero al terminar la ventana.
- Un procesador que reacciona a métricas de CloudWatch (conexiones de RDS, métricas custom de la aplicación, etc.).
Si solo necesitás escalar por CPU/memoria del Pod, el HPA nativo es suficiente — pero KEDA también puede modelar ese caso (mirá el template de CPU/memoria más abajo) si querés tener todas las reglas de escalado en un solo lugar.
¿Cómo instalo KEDA en mi Clúster?
Desde la consola de SleakOps:
- Abrí la sección Clusters y localizá el Clúster destino.
- Hacé clic en Manage Addons en la tarjeta del Clúster.
- En la lista de addons buscá Keda y abrí su panel de detalle.
- (Opcional) Agregá una o más policies de AWS en AWS Managed Policy Names — mirá la próxima FAQ.
- Hacé clic en Install.
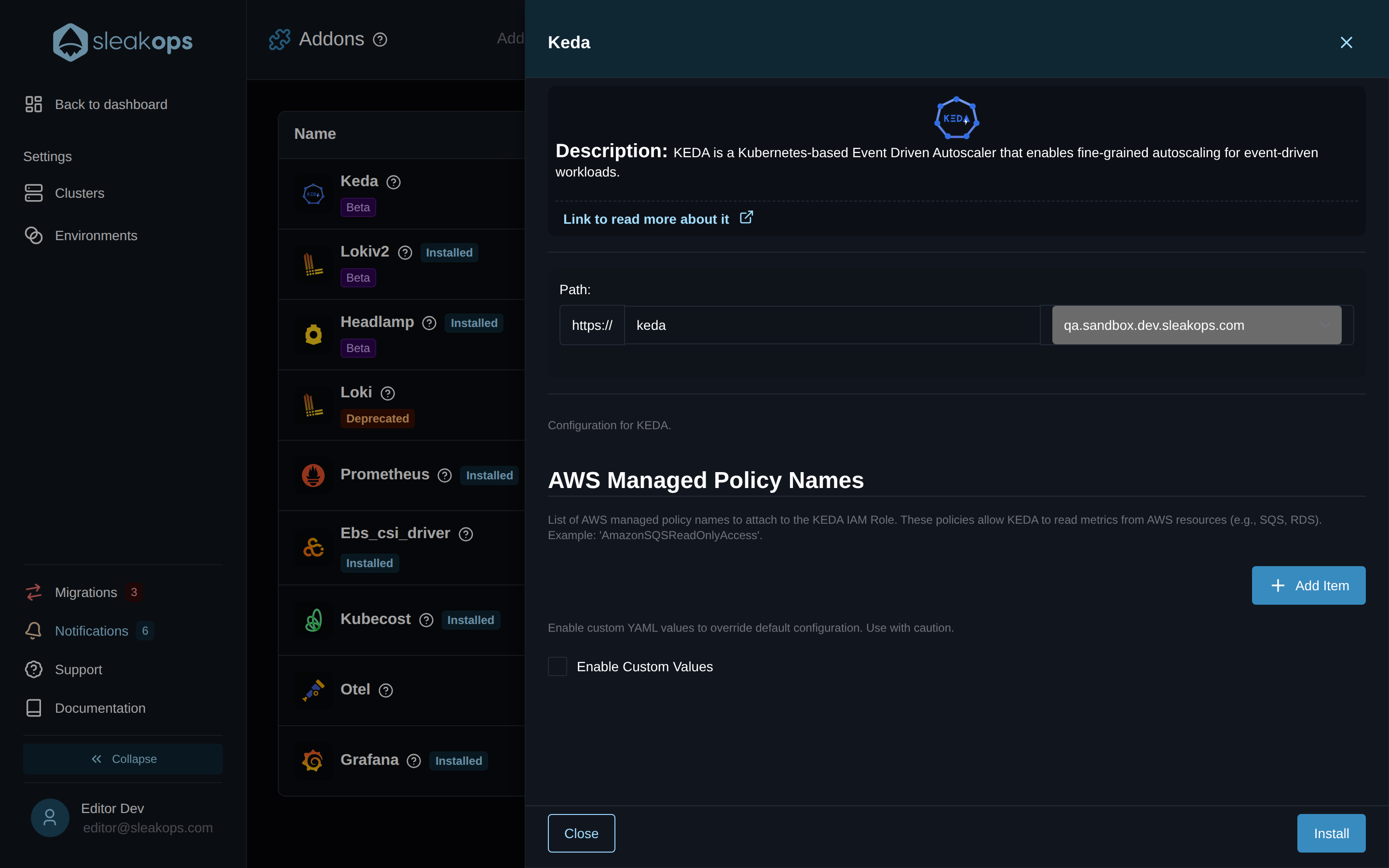
SleakOps despliega el operador de KEDA, su metrics adapter, los admission webhooks, y la ServiceAccount con el rol de IAM asociado. No hay que configurar nada adicional dentro del Clúster — una vez que aparezca como Installed en la lista de addons, KEDA queda listo para reaccionar a los ScaledObject que apliques en cualquier Namespace.
¿Qué pongo en "AWS Managed Policy Names"?
Los scalers de KEDA para AWS (SQS, CloudWatch, DynamoDB Streams, Kinesis, …) necesitan leer métricas de tu cuenta AWS para saber cuánto trabajo está pendiente. SleakOps le da a KEDA su propio rol de IAM mediante IRSA (IAM Roles for Service Accounts), y el campo AWS Managed Policy Names es donde listás las policies de AWS managed que ese rol debe llevar.
Agregá una entrada por policy — exactamente como AWS la escribe — por ejemplo:
| Si querés que KEDA escale en… | Agregá esta policy |
|---|---|
| Profundidad de cola SQS | AmazonSQSReadOnlyAccess |
| Métricas de CloudWatch | CloudWatchReadOnlyAccess |
| DynamoDB Streams | AmazonDynamoDBReadOnlyAccess |
| Métricas de Kinesis | AmazonKinesisReadOnlyAccess |
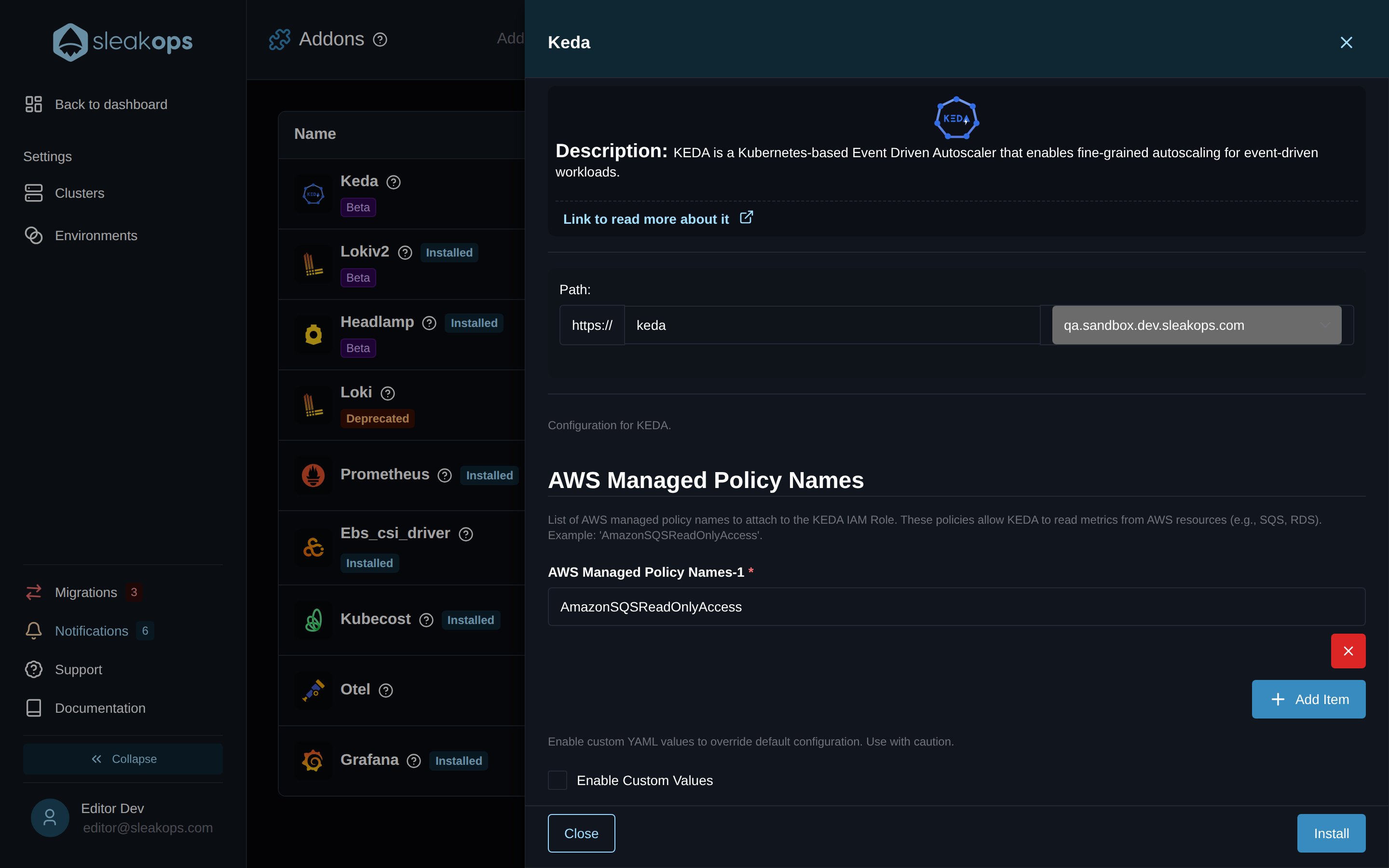
Podés dejar la lista vacía si solo vas a usar triggers que no son de AWS (Kafka, Redis, cron, RabbitMQ, …) — KEDA se instala igual y funciona para esos casos. Las policies se pueden agregar o quitar después reabriendo el panel del addon y haciendo clic en Update.
KEDA solo necesita leer métricas. Quedate con las *ReadOnlyAccess — no hay caso en el que KEDA tenga que escribir en una cola, un stream, o una tabla.
¿Cómo escalo concretamente un Workload con KEDA?
KEDA se configura a través de manifiestos de Kubernetes que vos definís junto al Workload. SleakOps no los genera — los aplicás vos (vía kubectl apply, Helm, o el pipeline de manifiestos que use tu Proyecto). Los dos patterns abajo cubren la mayoría de los casos.
Pattern 1 — Escalar según la profundidad de una cola SQS (event-driven)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: order-worker-scaler
namespace: my-app
spec:
scaleTargetRef:
name: order-worker # el Deployment a escalar
minReplicaCount: 0 # bajar a cero cuando no hay trabajo
maxReplicaCount: 20
pollingInterval: 30 # consultar la cola cada 30 segundos
cooldownPeriod: 300 # esperar 5 min de inactividad antes de bajar a 0
triggers:
- type: aws-sqs-queue
authenticationRef:
name: keda-aws-trigger-auth
metadata:
queueURL: https://sqs.us-east-1.amazonaws.com/123456789012/orders
queueLength: "10" # un Pod cada 10 mensajes en la cola
awsRegion: us-east-1
identityOwner: operator # usar la ServiceAccount de KEDA (IRSA)
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-aws-trigger-auth
namespace: my-app
spec:
podIdentity:
provider: aws # KEDA lee SQS con el rol de IAM
# que SleakOps asoció vía awsPolicyNames
El TriggerAuthentication es lo que conecta el manifiesto con el rol IRSA que configuró SleakOps — por eso ingresar AmazonSQSReadOnlyAccess en el formulario del addon es lo único que hace falta del lado AWS.
Pattern 2 — Escalar según CPU y memoria (reemplazo del HPA)
Si lo que querés es un escalado tipo HPA con más opciones, KEDA también lo cubre sin necesidad de triggers externos ni permisos de AWS:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: web-api-scaler
namespace: my-app
spec:
scaleTargetRef:
name: web-api
minReplicaCount: 2 # mantener al menos 2 réplicas activas
maxReplicaCount: 12
triggers:
- type: cpu
metricType: Utilization
metadata:
value: "70" # escalar cuando el uso promedio de CPU > 70%
- type: memory
metricType: Utilization
metadata:
value: "80"
Para el catálogo completo de triggers (Kafka, Redis, Prometheus, cron, NATS, MongoDB, …) consultá la documentación de KEDA Scalers .
¿Cómo aplico manifiestos de ScaledObject desde SleakOps?
ScaledObject desde SleakOps?Podés entregar manifiestos de ScaledObject (y TriggerAuthentication) a tu Clúster sin salir de la consola de SleakOps. Hay dos caminos — elegí en base a dónde tiene que vivir el manifiesto.
Opción 1 — Custom Values del addon de KEDA (extraObjects, scope cluster)
El Helm chart de KEDA expone una lista extraObjects que despliega cualquier manifiesto de K8s junto al operador. Abrí el panel de detalle del addon de KEDA, activá Enable Custom Values, y pegá el YAML:
extraObjects:
- apiVersion: keda.sh/v1alpha1
kind: ClusterTriggerAuthentication
metadata:
name: aws-irsa
spec:
podIdentity:
provider: aws
- apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: order-worker-scaler
namespace: my-app
spec:
scaleTargetRef:
name: order-worker
minReplicaCount: 0
maxReplicaCount: 20
triggers:
- type: aws-sqs-queue
authenticationRef:
kind: ClusterTriggerAuthentication
name: aws-irsa
metadata:
queueURL: https://sqs.us-east-1.amazonaws.com/123456789012/orders
queueLength: "10"
awsRegion: us-east-1
Estos recursos quedan asociados al release del addon de KEDA, lo que hace de este el camino correcto para recursos cluster-scoped (ClusterTriggerAuthentication) y para cualquier ScaledObject cuyo namespace destino definas explícitamente en el manifiesto. Editar el YAML y hacer clic en Update vuelve a aplicar el conjunto in-place.
Opción 2 — Chart Configuration del Proyecto (scope namespace, por Proyecto)
Cuando el ScaledObject tiene que vivir en el mismo namespace que el Workload que escala, entregalo a través de Project > Settings > Chart Configuration. El campo Templates acepta YAML de templates de Helm que se renderiza como parte del release del Proyecto, así que {{ .Values.global.namespace }} resuelve al Environment correcto automáticamente:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: order-worker-scaler
namespace: {{ .Values.global.namespace }}
spec:
scaleTargetRef:
name: order-worker-deployment
minReplicaCount: 0
maxReplicaCount: 20
pollingInterval: 30
cooldownPeriod: 300
triggers:
- type: aws-sqs-queue
authenticationRef:
name: keda-aws-trigger-auth
metadata:
queueURL: https://sqs.us-east-1.amazonaws.com/123456789012/orders
queueLength: "10"
awsRegion: us-east-1
identityOwner: operator
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-aws-trigger-auth
namespace: {{ .Values.global.namespace }}
spec:
podIdentity:
provider: aws
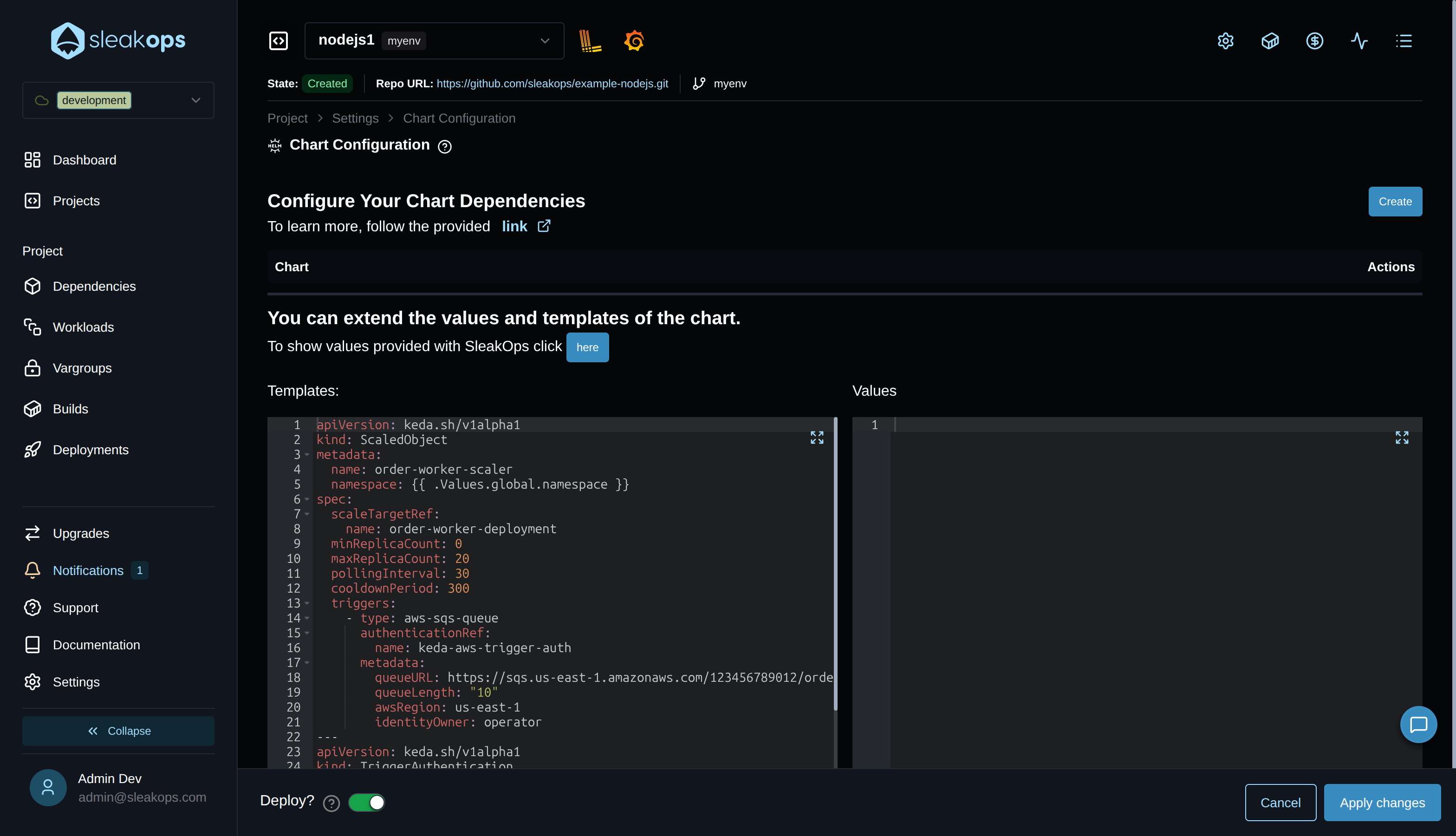
Con Deploy? activado, hacer clic en Apply changes dispara un nuevo deployment que aplica el manifiesto en el namespace del Proyecto — el camino correcto para reglas de escalado específicas de la aplicación que tienen que seguir al Proyecto entre Environments.
Para un walk-through completo, mirá el tutorial de Instalar KEDA.
¿Puedo personalizar el deployment de KEDA?
Sí. La configuración del addon expone un switch Enable Custom Values. Al activarlo aparece un editor YAML donde podés sobreescribir cualquier valor soportado por el Helm chart upstream de KEDA (cantidad de réplicas, resource requests, log level, namespaces a observar, …).
Los Custom Values sobreescriben los defaults que SleakOps valida como parte del addon. Valores mal configurados pueden romper el operador, el metrics adapter, o el cableado de IRSA. Mantené el diff chico y modificá únicamente las claves que entendés. Consultá los valores oficiales del Helm chart de KEDA para la referencia completa.