Web Service
Web Services son servicios que se ejecutan de forma continua y se encargan de gestionar interacciones basadas en HTTP, como servir páginas web, procesar solicitudes de API o administrar la autenticación de usuarios. En Kubernetes, cada Web Service se ejecuta en uno o varios pods que permanecen activos para responder a solicitudes externas en todo momento.
Preguntas Frecuentes
¿Cuál es la diferencia entre los esquemas de servicio Público, Privado e Interno?
- Público: Accesible a través de Internet y abierto a cualquier persona.
- Privado: Acceso restringido, disponible solo cuando se está conectado a la VPN.
- Interno: Solo accesible dentro del mismo clúster de Kubernetes y se utiliza para la comunicación interna entre servicios.
¿Cómo configuro el auto-escalado para mi Web Service?
Para habilitar el auto-escalado, puedes activar la opción Autoscaling y definir el Memory Target y el CPU Target. Estos objetivos determinan los umbrales de uso de recursos que desencadenan el auto-escalado. También debes especificar el número mínimo y máximo de réplicas que se deben mantener cuando el auto-escalado está habilitado.
¿Cuáles son los códigos de éxito predeterminados para un Web Service y puedo cambiarlos?
El código de éxito predeterminado es el 200, que indica que el servicio está sano. Puedes cambiar este código según los requisitos de tu aplicación, ya que algunos servicios pueden devolver diferentes códigos de éxito dependiendo de las acciones específicas.
¿Qué pasa si mi verificación de salud falla repetidamente?
Si la verificación de salud falla de manera consecutiva y alcanza el umbral de fallos (el valor predeterminado es 60), el servicio se marcará como no saludable, y Kubernetes podría reiniciar o terminar la instancia del servicio para intentar una recuperación.
¿Cómo puedo configurar la memoria y los ajustes de CPU para mi Web Service?
Puedes configurar la asignación de recursos para tu Web Service en el Paso 5: Finalizar la configuración al crear o actualizar el servicio:
- CPU Request: Los recursos mínimos de CPU garantizados para cada instancia
- CPU Limit: Los recursos máximos de CPU que cada instancia puede usar
- Memory Request: La memoria mínima garantizada para cada instancia
- Memory Limit: La memoria máxima que cada instancia puede usar
Importante - Comportamiento Predeterminado de SleakOps:
Si especificas valores de Request pero dejas los campos de Limit vacíos, SleakOps automáticamente establece los límites al 130% de los valores de request.
Por ejemplo:
- CPU Request =
1000m→ CPU Limit se convierte automáticamente en1300m - Memory Request =
512Mi→ Memory Limit se convierte automáticamente en665Mi
Para sobrescribir este valor predeterminado y establecer límites personalizados, simplemente especifica tus propios valores de CPU Limit y Memory Limit en el formulario de configuración. Se usarán tus valores personalizados en lugar del cálculo automático del 130%.
¿Cuáles son algunas buenas prácticas al configurar un Web Service en SleakOps?
- Siempre establece un mínimo de 2 réplicas para evitar el tiempo de inactividad.
- Asegúrate de que las rutas de verificación de salud y los códigos de éxito estén configurados correctamente para reflejar la verdadera salud de tu servicio.
- Usa auto-escalado siempre que sea posible para optimizar los recursos dinámicamente según la demanda.
- Revisa y ajusta adecuadamente los objetivos de memoria y uso de CPU para evitar sobrecargar tu infraestructura.
¿Qué debo hacer si mi servicio muestra tiempos de respuesta superiores a los 10 segundos?
Los tiempos de respuesta largos pueden indicar problemas como limitaciones de recursos, ineficiencias en la aplicación o problemas de red. Deberías revisar los registros de tu servicio, asegurarte de que los recursos (CPU, memoria) estén asignados adecuadamente y revisar el código de la aplicación para posibles optimizaciones.
¿Qué es el terminationGracePeriod y cómo lo configuro?
El terminationGracePeriod es una configuración de Kubernetes que define cuánto tiempo (en segundos) espera Kubernetes para que tu aplicación se detenga de forma ordenada antes de forzar su terminación. Esto es crucial para garantizar que tu servicio pueda finalizar el procesamiento de solicitudes activas, cerrar conexiones de base de datos o realizar operaciones de limpieza antes de apagarse.
Cómo funciona: Cuando Kubernetes necesita detener tu contenedor (durante un despliegue, un evento de escalado o un apagado), primero envía una señal SIGTERM a tu proceso y luego espera la cantidad de segundos definida por terminationGracePeriod antes de matar forzosamente el contenedor. La mayoría de los frameworks con los que construimos aplicaciones manejan SIGTERM automáticamente, pero si tenés algo personalizado, asegurate de que tu aplicación escuche SIGTERM y cierre correctamente todas sus conexiones y procesos en curso — de lo contrario, Kubernetes puede matar el contenedor mientras una operación está a medias.
Valor predeterminado: 30 segundos
Cuándo ajustarlo:
- Auméntalo si tu servicio necesita más tiempo para completar tareas de larga duración durante el apagado.
- Auméntalo si estás viendo terminaciones abruptas de conexiones o transacciones incompletas durante los despliegues.
- Disminúyelo si tu servicio se apaga rápidamente y deseas despliegues más rápidos.
Cómo configurarlo en SleakOps:
Al crear o actualizar un Web Service, puedes configurar el terminationGracePeriod en el Paso 4: Ajustes del servicio. Este campo te permite especificar el número de segundos que Kubernetes debe esperar antes de detener forzosamente tu servicio.
A través de Chart Templates:
También puedes configurar este valor a través de Chart Templates añadiéndolo a tus values:
terminationGracePeriodSeconds: 60 # Esperar 60 segundos antes de la terminación forzada
Esto le da a tu aplicación tiempo suficiente para manejar procedimientos de apagado ordenado, asegurando la integridad de los datos y una mejor experiencia de usuario durante actualizaciones u operaciones de escalado.
Como puedo desplegar mi sitio web estatico?
Por el momento, Sleakops no ofrece soporte nativo para sitios estáticos. Sin embargo, puedes desplegarlos utilizando el mismo flujo que para otros sitios, contenedorizándolos con un servidor web como Nginx. A continuación, se muestra un ejemplo sencillo de un Dockerfile y su correspondiente nginx.conf para servir tu contenido estático.
FROM node:20.11.0-alpine AS base
WORKDIR /app
FROM base AS build
ARG BACKEND_URL
WORKDIR /app
COPY package.json package-lock.json ./
RUN npm install
COPY . ./
RUN npm run build
FROM nginx:1.25.3-alpine AS production
COPY --from=build /app/config/nginx.conf /etc/nginx/conf.d/default.conf
COPY --from=build /app/dist /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
Un ejemplo de config/nginx.conf:
server {
listen 80;
location = /health {
access_log off;
add_header 'Content-Type' 'application/json';
return 200 '{"status":"OK"}';
}
location / {
root /usr/share/nginx/html;
index index.html index.htm;
try_files $uri $uri/ /index.html =404;
add_header Last-Modified $date_gmt;
add_header Cache-Control 'no-store, no-cache';
if_modified_since off;
expires off;
etag off;
}
}
Utilizando este enfoque basado en Docker, puedes servir tu sitio estático con Nginx, todo dentro de un contenedor.
Añadir un Web Service para tu Proyecto
1. Navegar a la sección de crear un Web Service
En el Panel izquierdo, accede a Workloads. Luego selecciona la pestaña Servicios Web y, en la esquina superior derecha, haz clic en el botón Crear.
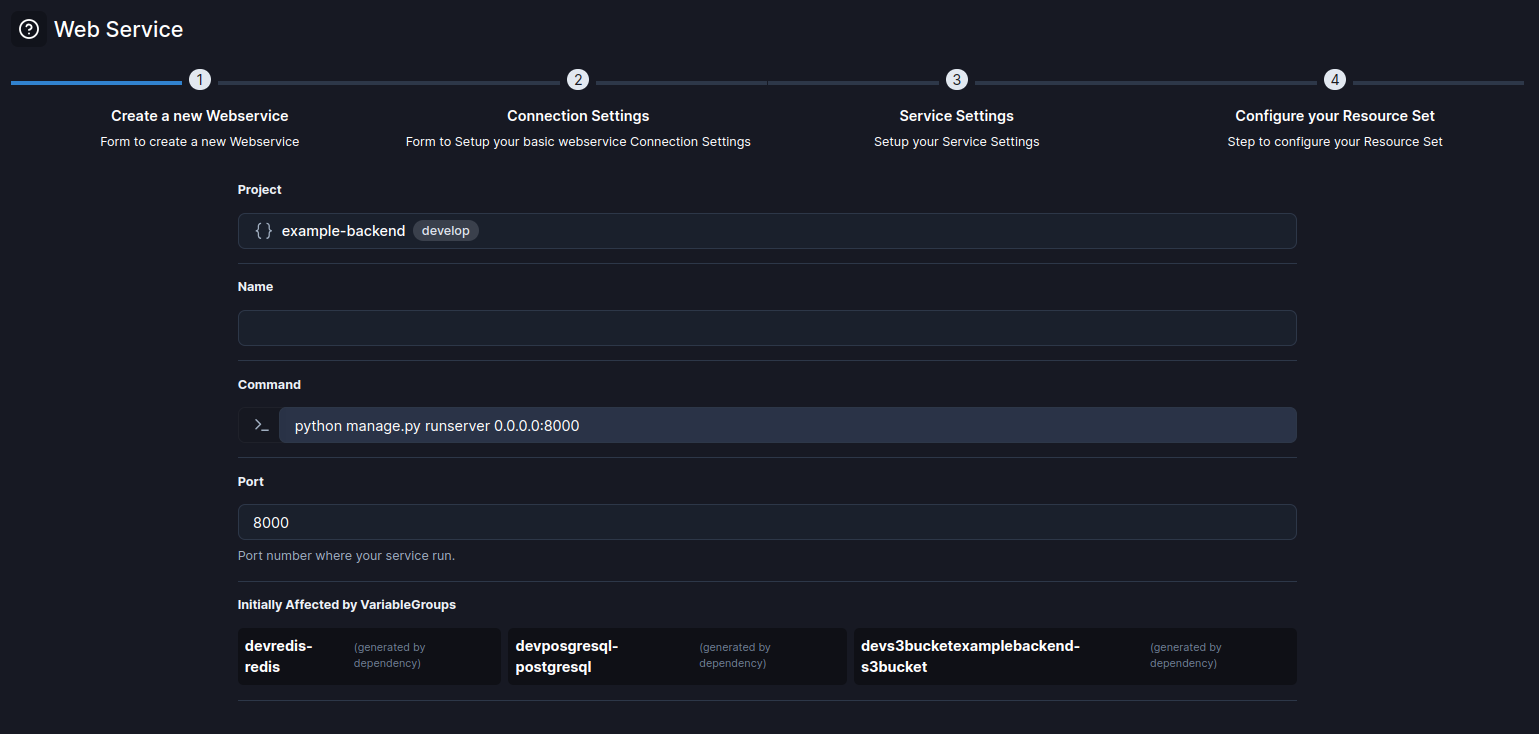
2. Selecciona un Proyecto y un Nombre para el Web Service
Comienza con la información básica, completa estos atributos y haz clic en Siguiente para continuar.
| Atributo | Descripción |
|---|---|
| Nombre | Identifica tu Web Service. |
| Proyecto | Selecciona entre los proyectos existentes. |
| Comando | El comando que ejecuta el servicio. |
| Puerto | El número de puerto donde se ejecuta el servicio. Predeterminado: 8000 |
Una vez completados estos atributos, haz clic en el botón Siguiente para continuar.
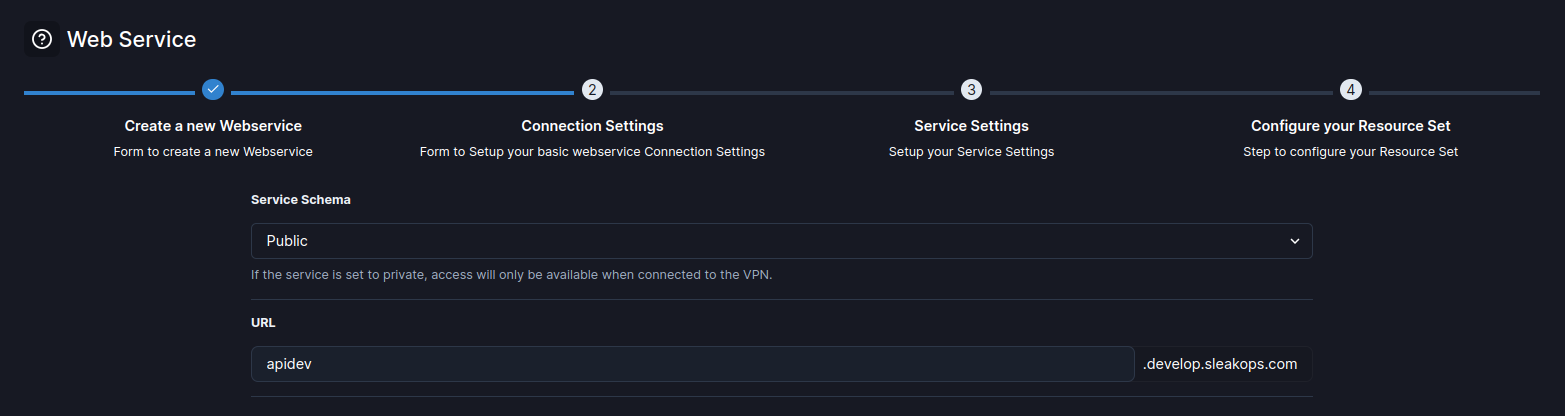
3. Define la conexión
Selecciona cómo será tu conexión y haz clic en Siguiente.
| Atributo | Descripción |
|---|---|
| Esquema de Servicio | Define la accesibilidad del servicio: público, privado o interno. |
| URL | La URL asignada al servicio según el entorno y la configuración del proyecto. Formato: name.myenv.sleakops.com. |
4. Especifica los ajustes de tu servicio
Verás los siguientes atributos para especificar las condiciones.
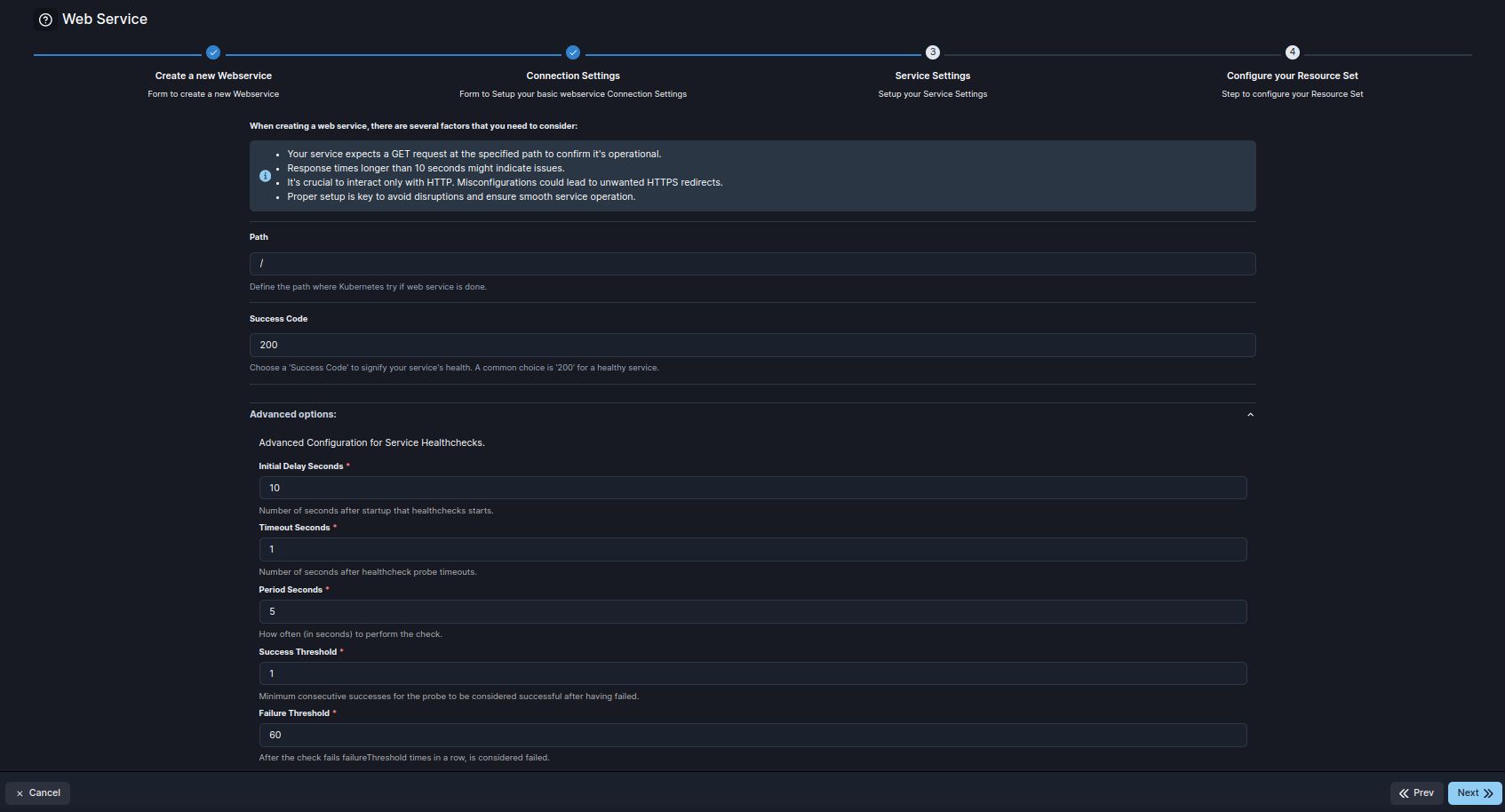
| Atributo | Descripción |
|---|---|
| Ruta | La ruta donde Kubernetes verifica si el Web Service está operativo. Predeterminado: / |
| Código de Éxito | El código HTTP de éxito que indica la salud del servicio. Predeterminado: 200. |
| Retraso Inicial en Segundos | Número de segundos después del inicio antes de que comiencen las verificaciones de salud. Predeterminado: 10. |
| Segundos de Tiempo de Espera | Número de segundos después del inicio antes de que comiencen las verificaciones de salud. Predeterminado: 1. |
| Segundos entre cada Verificación | Intervalo (en segundos) entre cada prueba de verificación de salud. Predeterminado: 5. |
| Umbral de Éxitos | Número mínimo de éxitos consecutivos requeridos para que la prueba se considere exitosa después de fallar. Predeterminado: 1. |
| Umbral de Fallos | Número de fallos consecutivos antes de que la prueba se considere fallida. Predeterminado: 60. |
| terminationGracePeriod | Tiempo en segundos que Kubernetes espera para el apagado ordenado antes de terminar forzosamente el servicio. Predeterminado: 30. |
Una vez completados estos atributos, haz clic en el botón Siguiente para continuar con el siguiente paso.
5. Finalizar la configuración
Este paso describe los atributos clave para configurar los recursos de un Servicio Web en SleakOps, permitiendo una gestión flexible de CPU, memoria y comportamientos de escalado.
| Atributo | Descripción |
|---|---|
| CPU Request | La cantidad mínima de recursos de CPU asignados para cada instancia en el clúster. Esto garantiza que cada instancia siempre tenga esta cantidad de CPU disponible. |
| CPU Limit | La cantidad máxima de recursos de CPU que cada instancia en el clúster puede utilizar. Este límite ayuda a prevenir que una instancia consuma demasiada CPU. |
| Memory Request | La cantidad mínima de memoria asignada para cada instancia en el clúster. Esto garantiza que la instancia tenga suficiente memoria para operar eficientemente. |
| Memory Limit | La cantidad máxima de memoria que cada instancia en el clúster puede utilizar. Limita el uso de memoria para evitar que una sola instancia consuma recursos en exceso. |
| Autoscaling | Activar o desactivar el auto-escalado. Cuando está habilitado, permite que el servicio ajuste el número de réplicas según la demanda y el uso de recursos. |
| CPU Target | El porcentaje de uso de CPU que desencadena el auto-escalado. Si el uso supera este objetivo, se pueden desplegar réplicas adicionales para equilibrar la carga. |
| Memory Target | El porcentaje de uso de memoria que activa el ajuste de auto-escalado. Cuando las instancias superan este objetivo, el sistema escala hacia arriba para acomodar la demanda. |
| Replicas Min | El número mínimo de réplicas que deben mantenerse cuando el auto-escalado está activo. Un mínimo de 2 réplicas garantiza alta disponibilidad y previene tiempos de inactividad. |
| Replicas Max | El número máximo de réplicas que se pueden desplegar cuando el auto-escalado está habilitado. Establece un límite superior en el número de instancias para evitar la sobreasignación de recursos. |
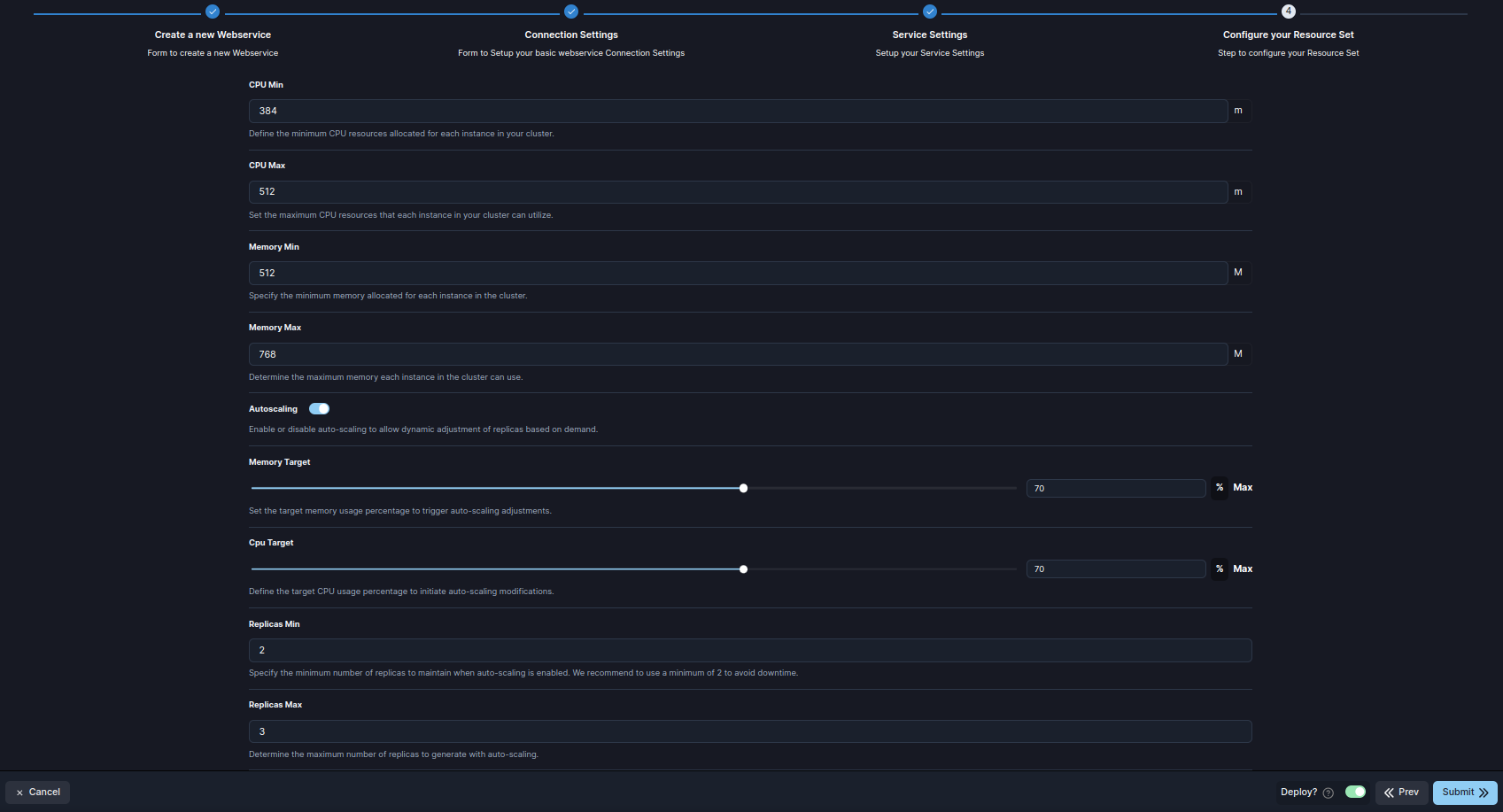
Envía para crear y desplegar tu web service.